# [EDA]] 이상치 체크 및 시각화 함수
2024. 12. 17. 15:05ㆍ인공지능/머신러닝
📌 본 포스팅은 이상치를 체크하고 시각화하는 내용을 다룹니다.
- 비정상적이지만 중요할 수잇는 데이터 포인트 발견 , 통계기법과 알고리즘 접근법 , Z-score, DBSCAN, LOF 다변량 기법
- 단변량 이상치, 다변량 이상치 탐지
1. 데이터에 숨이있는 이상치의 비밀과 영향
- 다른값과 현저히 다른 데이터 , 오류, 실수, 예상치 못한 중요한 현상 반영 하기도함.
- 이상치는 종종 숨겨진 비밀을 풀어나가는 열쇠 , 잘못하면 분석 결과를 왜곡.
1.1 정의
- 좀 특별해, 새로운 관점이나 중요한 정보.
1.2 원인
- 인간적인실수, 데이터 손상, 실제로 예외적인 일( 이상치로 단정지어버리면 안되고 원인 분석을 하고 패턴에서 위치 이해).
1.3 유형
- 단변량 이상치 : 변수하나에서 이상한 값.
- 다변량 이상치 : 변수 여러개를 고려할때 이상한값. ex) 이상하게 키에 비해 몸무게가 너무 적거나 많ㅇ르 때
1.4 데이터에 미치는 영향
- 예측의 오차가 커짐. 일반적인 리듬이 깨짐, 결과가 한쪽으로 치우침, 분석의 기본규칙이 흔들림.
1.5 이상치 유무 데이터 차이
- 이상치가 있으면 평균이 크게 증가하거나 표준편차도 크게 늘어나 분산이 높아짐.
2. 단변량 이상치 탐지
- Z-score, IQR(Interquartile Range) , 중고차 가격 예측 데이터 셋,
2.1 이상치 발견하는 법
- Z-score : 데이터 표준편차를 활용해 감지하는 간단, 강력,
- IQR : 사분위 범위, 데이터의 중앙값 기준 정상범위 벗어나는 데이터 Q1,Q3 계산 이후 IQR 구함.
- DBSCAN (Densitiy-Based Spatial Clustering of Application with Noise): 데이터 포인트 그룹화 하여 이상치 식별, 클러스터링 알고리즘, 데이터포인트의 밀도 기반, 주변 데이터 포인트와의 관계를 고려하여 이상치 탐지
- LOF(Local Outlier Factor ): LOF 는 데이터의 지역적 밀도를 측정함. 주변 포인트의 밀도와 비교하여 이상치를 탐지함. 데이터의 지역적 밀도가 다를때 효과 적임.
2.2 Z score 활용
- 데이터 세트 내 각 데이터 포인트의 상대적 위치 수치화, z = (x-u)/sigma
- Z=0(데이터 포인트가 평균값에 정확히 일치, >0 높음,<0 낮음>), ex) 2이상은 이상치일 가능성이 높음. (moderately unusual)
- Z score 직접 계산후 이상치 제거함, Scipy 를 이용한 계산과 제거 Scipy, stats 모듈
- 탐지전 histogram
3. IQR 을 활용하여 이상치 발견해보기
3.1 정의
- 중간 범위를 측정하는 통계법, 데이터 중간값 주변 변동성 파악 , Q1~Q3 까지가 IQR임
- 이상치 경계 설정 하한경계 : Q1 - 1.5IQR , IQR = Q3-Q1, 상한경계 : Q3 + 1.5IQR
- pandas quantile 함수를 사용하여 계산 가능 , numpy percentile 함수를 사용하여 계산가능.
- 상자수염 그림으로 확인
3.2 IQR 장단.
- 극단치에 대한 강한 내성, 비대칭적 분포 일때 유용, 직관적 이해 사분위수 사용, 비모수적 접근 데이터가 정규분포가 아닌경우에도 사용 가능.
- 정보손실 가능성 . 임의의 임계값 설정. 1.5*IQR 은 임의 적임. 명확한 가이드라인이 없음.
- 데이터의 성격과 목적에 따라 신중하게 결정해야함.
3.3 이상치에 대한 다른 대치법
- 데이터 변환 => 로그 변환, 제곱근, 역수 등 데이터 분포를 조절 가능.
- 이상치 점수화 : 이상치를 식별하고 점수화 할수잇음. 점수를 호라용하여 모델에 활용하거나 이상치의 정도를 파악가능
- 모델기반 접근 : 일부 머신 러닝 모델은 이상치에 강건하며 이상치를 자동으로 처리할 수잇음. 트리기반 모델은 이상치에 민감하지 않음.
- 이상치를 고려한 모델링: 이상치가 중요한 정보를 제공하는경우 제거하지않고 모델링을 수행하고 결과에 미치는 영향을 조사하는 것이 유용할 수있음.
4.함수 제작 및 실행
- 신용카드 사기 거래 탐지 데이터 (데이콘 출처 )
- output target 의 분포와 box plot 으로 분포를 확인
- z score 가 3 이상인 구간은 붉게 색칠함.
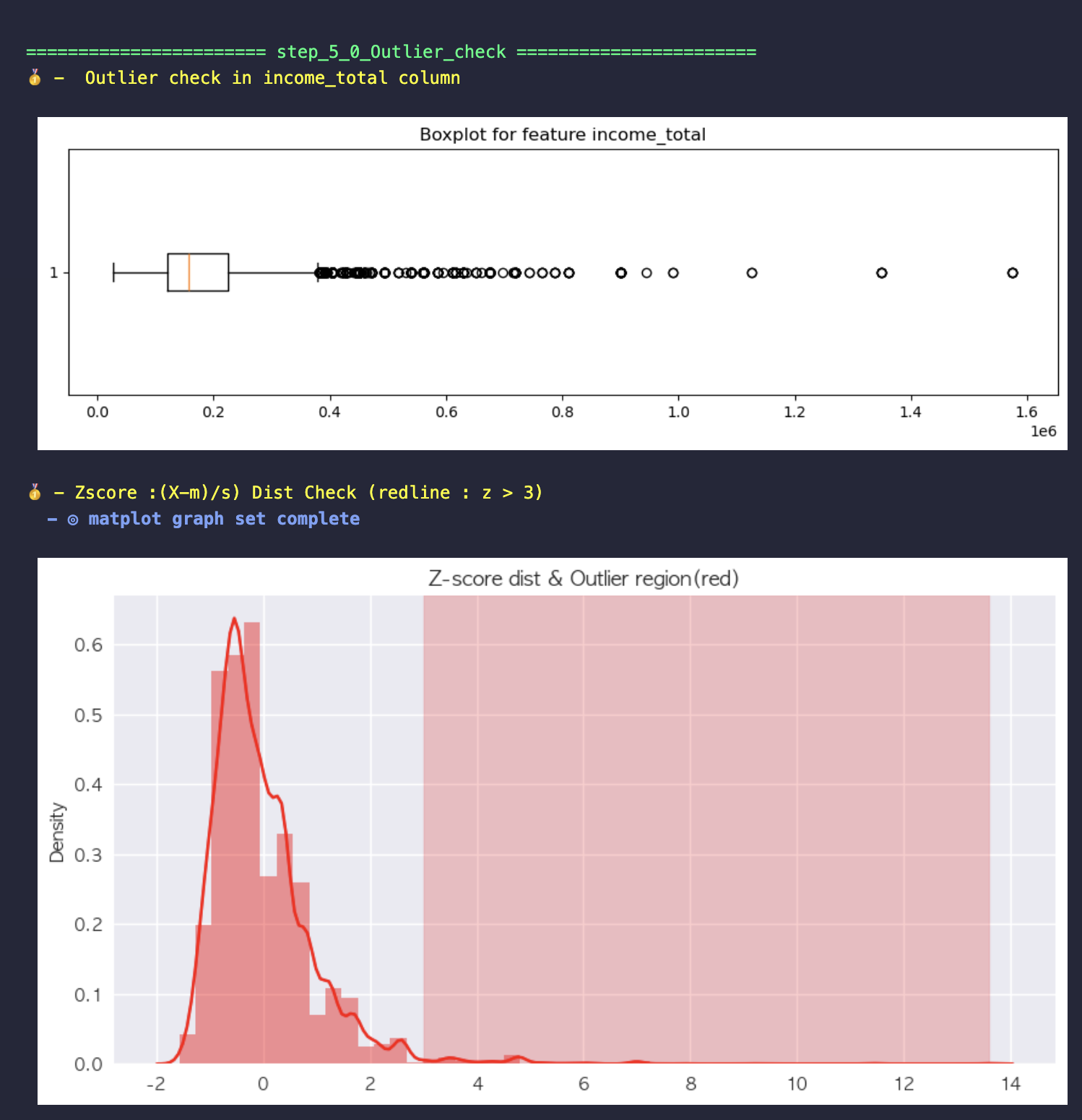
## 5-0: [EDA] 이상치 시각화 및 확인
def step_5_0_Outlier_check(train, target='income_total'):
"""
# # Outlier of target column
## outlier_value = step_5_0_Outlier_check(X_train, target=target)
"""
print(r_cy("\n======================= step_5_0_Outlier_check ======================="))
import matplotlib.pyplot as plt , seaborn as sns
import numpy as np
def out_zscore(data, threshold =3):
mean = np.mean(data)
std = np.std(data)
zscores = [(x-mean)/std for x in data]
outliers = [x for x in data if np.abs((x- mean)/std)> threshold]
return zscores, len(outliers)
zscores ,num_outliers = out_zscore(train[target])
y(f" - Outlier check in {target} column")
plt.figure(figsize= (12,3))
plt.boxplot(train[target], vert = False)
plt.title(f"Boxplot for feature {target}")
plt.show()
y(" - Zscore :(X-m)/s) Dist Check (redline : z > 3)")
plt.figure(figsize =(10,5))
plotSetting()
sns.distplot(zscores, color='red')
plt.axvspan(xmin= 3, xmax = max(zscores), alpha =0.2, color= 'red')
plt.title("Z-score dist & Outlier region(red)")
plt.show()
outlier_value=np.mean(train[target])+np.std(train[target])*3
y_(f" - Total number of outliers are {num_outliers} : {target}> {outlier_value}")
return outlier_value'인공지능 > 머신러닝' 카테고리의 다른 글
| # [EDA] 데이터 불균형 해결을 위한 SMOTE oversampling (3) | 2024.12.17 |
|---|