2024. 12. 31. 11:18ㆍ개발/웹 스크래핑
나라장터란 무엇이고 거기서 얻을수있는 정보는 무엇인가? pretotyping 부터 시작해서 크롤링 서비스를 만들어 보자.
🤔 나라장터란?
✅ 나라장터란 는 모든 공공 기관의 입찰 정보가 공고된 국가 종합 전자 조달 시스템 이다.
1.입찰 공고 검색 Process
1) 웹사이트에서 클릭하며 공고 검색
💻 입찰 공고 명 검색 > 공고 선택 > 공고 확인
공고 검색
공고 선택
공고 확인 
2. Inspect 를 사용하여 페이지 구조 분석
1) Inspect 창에서 요소확인
💻 inspect 창 좌상단 아이콘 클릭 > 검색버튼 마우스오버 > inspect 요소확인인
inspect 확인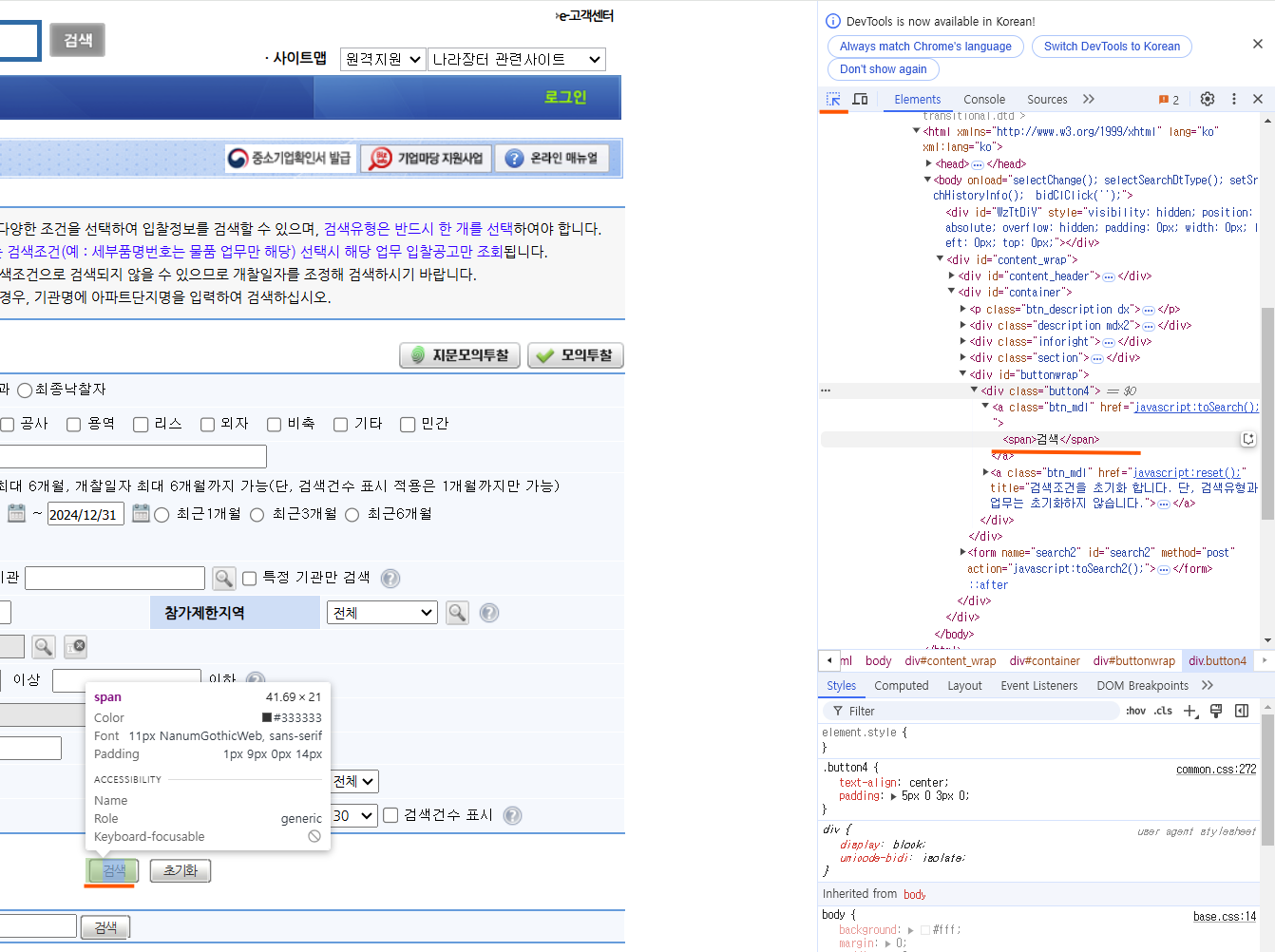
inspect 구조확인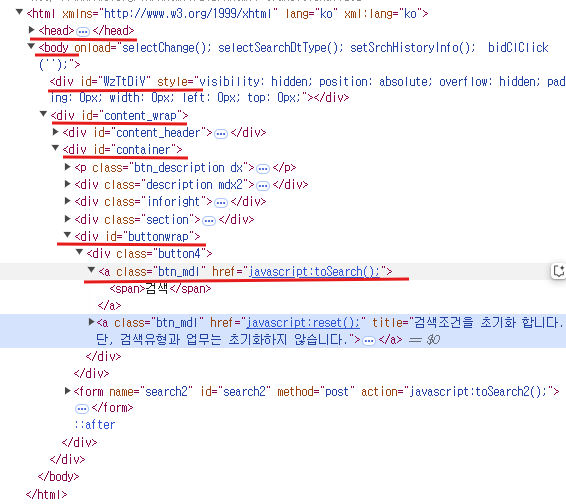
3. 검색 버튼 요소 접근
1) 버튼 위치에서 XPATH element 추출후 실행
💻 inspect 창 > <a class= ~ > 우클릭 > Copy XPATH 클릭 > 파이썬 코드 실행
//*[@id="buttonwrap"]/div/a[1] 을 복사하여 다음과 같이 실행
def site_open(addr):
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import requests
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get(addr)
## 검색 버튼 << 요소 탐색
검색버튼 = driver.find_element(By.XPATH, '//*[@id="buttonwrap"]/div/a[1]')
nara_address="https://www.g2b.go.kr/pt/menu/selectSubFrame.do?framesrc=/pt/menu/frameTgong.do?url=https://www.g2b.go.kr:8101/ep/tbid/tbidFwd.do"
site_open(nara_address)4. No such element Error 해결

[에러 이유]
사이트의 프레임이 나뉘어져 있음.
frame 을 이동하지 않고 초기 지정된 첫번 째 frame 에서 요소를 탐색하기 때문에 발생하는 에러임.
frame 만 보이게 토글을 접어서 frame name 확인
기본 설정된 default frame src 는 총 3개 의 프레임이 있으며 각각의 ID 는 top,sub, hdn 이다.
검색 버튼은 frame id = 'sub' 에 담겨 있다.
5. 코드로 프레임 구조 파악

6. 원하는 프레임으로 들어가서 검색 버튼 클릭
driver.switch_to.frame('sub') ## frame id 로 switch
current_frame = driver.execute_script('return window.frameElement.id;')
print(f" - 현재 프레임 : {current_frame}")
## main 으로 들어가기
driver.switch_to.frame("main")
current_frame_01 = driver.execute_script("return window.frameElement.name;")
print(f" - 현재 프레임 : {current_frame} >> {current_frame_01}")
# 검색 버튼 << 요소 탐색색
검색버튼 = driver.find_element(By.XPATH, '//*[@id="buttonwrap"]/div/a[1]')
검색버튼.click()코드를 실행하면 다음과 같이 검색버튼이 클릭된것을 볼 수 있다.
7. 전체코드
def site_open(addr):
import selenium
# help(selenium)
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import requests
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get(addr)
# default frame 에서 모든 frame 요소 가져오기
driver.switch_to.default_content() # 기본문서로 돌아가기
frames = driver.find_elements(By.TAG_NAME, 'frame')
print("현 페이지에서의 Frame 구조")
for order,frame in enumerate(frames):
frame_name = frame.get_attribute('name')
print(f" {order+1} : {frame_name}")
print(f'frame 총 개수 :{len(frames)}')
driver.switch_to.frame('sub') ## frame id 로 switch
current_frame = driver.execute_script('return window.frameElement.id;')
print(f" - 현재 프레임 : {current_frame}")
## main 으로 들어가기
driver.switch_to.frame("main")
current_frame_01 = driver.execute_script("return window.frameElement.name;")
print(f" - 현재 프레임 : {current_frame} >> {current_frame_01}")
# 검색 버튼 << 요소 탐색색
검색버튼 = driver.find_element(By.XPATH, '//*[@id="buttonwrap"]/div/a[1]')
검색버튼.click()
nara_address="https://www.g2b.go.kr/pt/menu/selectSubFrame.do?framesrc=/pt/menu/frameTgong.do?url=https://www.g2b.go.kr:8101/ep/tbid/tbidFwd.do"
site_open(nara_address)
📌 참고 1.나라장터 홈페이지,나라장터정의
📌 참고 2.블로그, 202, 나라장터 크롤링
'개발 > 웹 스크래핑' 카테고리의 다른 글
| [crawling]나라장터 크롤링 하기 (2) | 2024.12.24 |
|---|---|
| # [크롤링] 필수 HTML 태그 지식 에 대하여 (2) | 2024.12.17 |
| # [크롤링] 웹 크롤링 하기 01 (3) | 2024.12.17 |